Tutoriel
import numpy as np
import pandas as pd
Lire des données d’observation
Au format XML-SANDRE (export HydroPortail)
from evalhyd.vigicrues.read import read_obs_from_xml_sandre
df_obs = read_obs_from_xml_sandre(['tutoriel/data/obs/export_hydro_series.xml'])
print(df_obs)
valeur
entite date_validite
H5201010 2010-01-01 165549.0
2010-01-02 183860.0
2010-01-03 186781.0
2010-01-04 165038.0
2010-01-05 130174.0
... ...
H507101002 2019-12-28 111972.0
2019-12-29 112633.0
2019-12-30 97809.0
2019-12-31 92378.0
2020-01-01 72622.0
[18039 rows x 1 columns]
Au format CSV (export HydroPortail)
from evalhyd.vigicrues.read import read_obs_from_csv_hydroportail
df_obs = read_obs_from_csv_hydroportail(
['tutoriel/data/obs/K1180010_QmnH(n=1_non-glissant).csv',
'tutoriel/data/obs/K1440010_QmnH(n=1_non-glissant).csv']
)
print(df_obs)
valeur
entite date_validite
K1180010 2024-12-11 00:00:00 137.0
2024-12-11 01:00:00 135.0
2024-12-11 02:00:00 133.0
2024-12-11 03:00:00 132.0
2024-12-11 04:00:00 130.0
... ...
K1440010 2024-12-16 19:00:00 159.0
2024-12-16 20:00:00 166.0
2024-12-16 21:00:00 171.0
2024-12-16 22:00:00 174.0
2024-12-16 23:00:00 178.0
[288 rows x 1 columns]
Lire des données de prévision
Au format XML-SANDRE
from evalhyd.vigicrues.read import read_prd_from_xml_sandre
Prévisions en scénarios
df_prd = read_prd_from_xml_sandre(
['tutoriel/data/prd/GRP_B_20241211_1023_5304.xml']
)
print(df_prd)
valeur
entite echeance membre date_validite
K0045510 0 days 01:00:00 0001 2024-12-11 11:00:00 558.0
0002 2024-12-11 11:00:00 558.0
0003 2024-12-11 11:00:00 558.0
0004 2024-12-11 11:00:00 558.0
0005 2024-12-11 11:00:00 558.0
... ...
K0114030 5 days 00:00:00 0046 2024-12-16 10:00:00 1644.0
0047 2024-12-16 10:00:00 1645.0
0048 2024-12-16 10:00:00 2973.0
0049 2024-12-16 10:00:00 2294.0
0050 2024-12-16 10:00:00 1644.0
[12000 rows x 1 columns]
Prévisions en tendances
df_prd = read_prd_from_xml_sandre(
['tutoriel/data/prd/Prev_E_20190103_0819_20190103_0913.xml'], seek_issue_date=False
)
print(df_prd)
valeur
entite echeance tendance date_validite
K1900010 0 moy 2019-01-03 08:00:00 82333.602905
min 2019-01-03 08:00:00 81426.399231
max 2019-01-03 08:00:00 84066.703796
1 moy 2019-01-03 09:00:00 82662.200928
min 2019-01-03 09:00:00 81431.999206
... ...
K1440010 23 min 2019-01-04 06:00:00 56033.599854
max 2019-01-04 06:00:00 59190.799713
24 moy 2019-01-04 07:00:00 57676.700592
min 2019-01-04 07:00:00 56052.898407
max 2019-01-04 07:00:00 59300.498962
[1515 rows x 1 columns]
Au format PRV
from evalhyd.vigicrues.read import read_prd_from_prv
Prévisions en scénarios
df_prd = read_prd_from_prv(
['tutoriel/data/prd/GRP_B_20241211_1023_5304.prv']
)
print(df_prd)
valeur
entite echeance membre date_validite
K0045510 0 days 01:00:00 0001 2024-12-11 11:00:00 0.558
0002 2024-12-11 11:00:00 0.558
0003 2024-12-11 11:00:00 0.558
0004 2024-12-11 11:00:00 0.558
0005 2024-12-11 11:00:00 0.558
... ...
K0673310 5 days 00:00:00 0046 2024-12-16 10:00:00 1.644
0047 2024-12-16 10:00:00 1.645
0048 2024-12-16 10:00:00 2.973
0049 2024-12-16 10:00:00 2.294
0050 2024-12-16 10:00:00 1.644
[120000 rows x 1 columns]
Prévisions en tendances
df_prd = read_prd_from_prv(
['tutoriel/data/prd/Prev_E_20241211_0706_20241211_0707_5159.prv',
'tutoriel/data/prd/Prev_E_20241211_0706_20241211_0707_5166.prv']
)
print(df_prd)
valeur
entite echeance tendance date_validite
K1180010 0 days 01:00:00 basse_10 2024-12-11 07:00:00 96.5315
centrale_50 2024-12-11 07:00:00 109.0000
haute_90 2024-12-11 07:00:00 120.3889
0 days 02:00:00 basse_10 2024-12-11 08:00:00 95.8804
centrale_50 2024-12-11 08:00:00 108.4000
... ...
K1440010 4 days 22:00:00 centrale_50 2024-12-16 04:00:00 201.5000
haute_90 2024-12-16 04:00:00 262.3933
4 days 23:00:00 basse_10 2024-12-16 05:00:00 140.5569
centrale_50 2024-12-16 05:00:00 201.5000
haute_90 2024-12-16 05:00:00 262.3933
[714 rows x 1 columns]
Évaluer des prévisions
Prévisions probabilistes
from evalhyd.vigicrues.evaluate import evalp
Prévisions en tendances
Seuls certains indicateurs sont calculables.
dict_df_prb = evalp(
df_obs=df_obs,
df_prd=df_prd,
metrics=['QS', 'CR', 'AW', 'AWN', 'WS', 'RANK_HIST'],
c_lvl=np.array([80])
)
df_qs = dict_df_prb['QS']
print(df_qs)
valeur
entite echeance sous_ensemble echantillon quantile
K1180010 0 days 01:00:00 1 aucun 0.250 15.23425
0.500 18.00000
0.750 9.91665
0 days 02:00:00 1 aucun 0.250 15.05980
0.500 17.60000
... ...
K1440010 4 days 22:00:00 1 aucun 0.500 32.50000
0.750 46.69665
4 days 23:00:00 1 aucun 0.250 13.72155
0.500 33.50000
0.750 47.19665
[714 rows x 1 columns]
Prévisions en scénarios
Tous les indicateurs sont calculables.
dict_df_prb = evalp(
df_obs=df_obs,
df_prd=df_prd,
metrics=['CRPS_FROM_ECDF', 'QS', 'CR', 'WS', 'REL_DIAG', 'RANK_HIST'],
q_thr=np.array([[89240.], [153000.]]),
events='high',
c_lvl=np.array([80])
)
df_crps = dict_df_prb['CRPS_FROM_ECDF']
print(df_crps)
valeur
entite echeance sous_ensemble echantillon
K1180010 0 days 01:00:00 1 aucun 13.058222
0 days 02:00:00 1 aucun 12.628456
0 days 03:00:00 1 aucun 12.691967
0 days 04:00:00 1 aucun 13.843389
0 days 05:00:00 1 aucun 14.791489
... ...
K1440010 4 days 19:00:00 1 aucun 23.734544
4 days 20:00:00 1 aucun 23.702433
4 days 21:00:00 1 aucun 24.036656
4 days 22:00:00 1 aucun 24.370533
4 days 23:00:00 1 aucun 24.704044
[238 rows x 1 columns]
Prévisions déterministes
from evalhyd.vigicrues.evaluate import evald
Il est nécessaire de travailler entité par entité pour le calcul d’indicateurs déterministes.
dict_df_dtm = evald(
df_obs=df_obs,
df_prd=df_prd.xs('centrale_50', level='tendance'),
metrics=['KGE', 'CONT_TBL'],
q_thr=np.array([[89240.], [153000.]]), events='high'
)
df_kge = dict_df_dtm['KGE']
print(df_kge)
valeur
entite echeance sous_ensemble echantillon
K1180010 0 days 01:00:00 1 aucun NaN
0 days 02:00:00 1 aucun NaN
0 days 03:00:00 1 aucun NaN
0 days 04:00:00 1 aucun NaN
0 days 05:00:00 1 aucun NaN
... ...
K1440010 4 days 19:00:00 1 aucun NaN
4 days 20:00:00 1 aucun NaN
4 days 21:00:00 1 aucun NaN
4 days 22:00:00 1 aucun NaN
4 days 23:00:00 1 aucun NaN
[238 rows x 1 columns]
Visualiser des indicateurs de prévision
Histogramme de rang
from evalhyd.vigicrues.plot import plot_rank_hist
filepaths_rank_hist = plot_rank_hist(dict_df_prb['RANK_HIST'], output_dir='tutoriel/figs')
from IPython.display import Image
Image(filepaths_rank_hist[0])
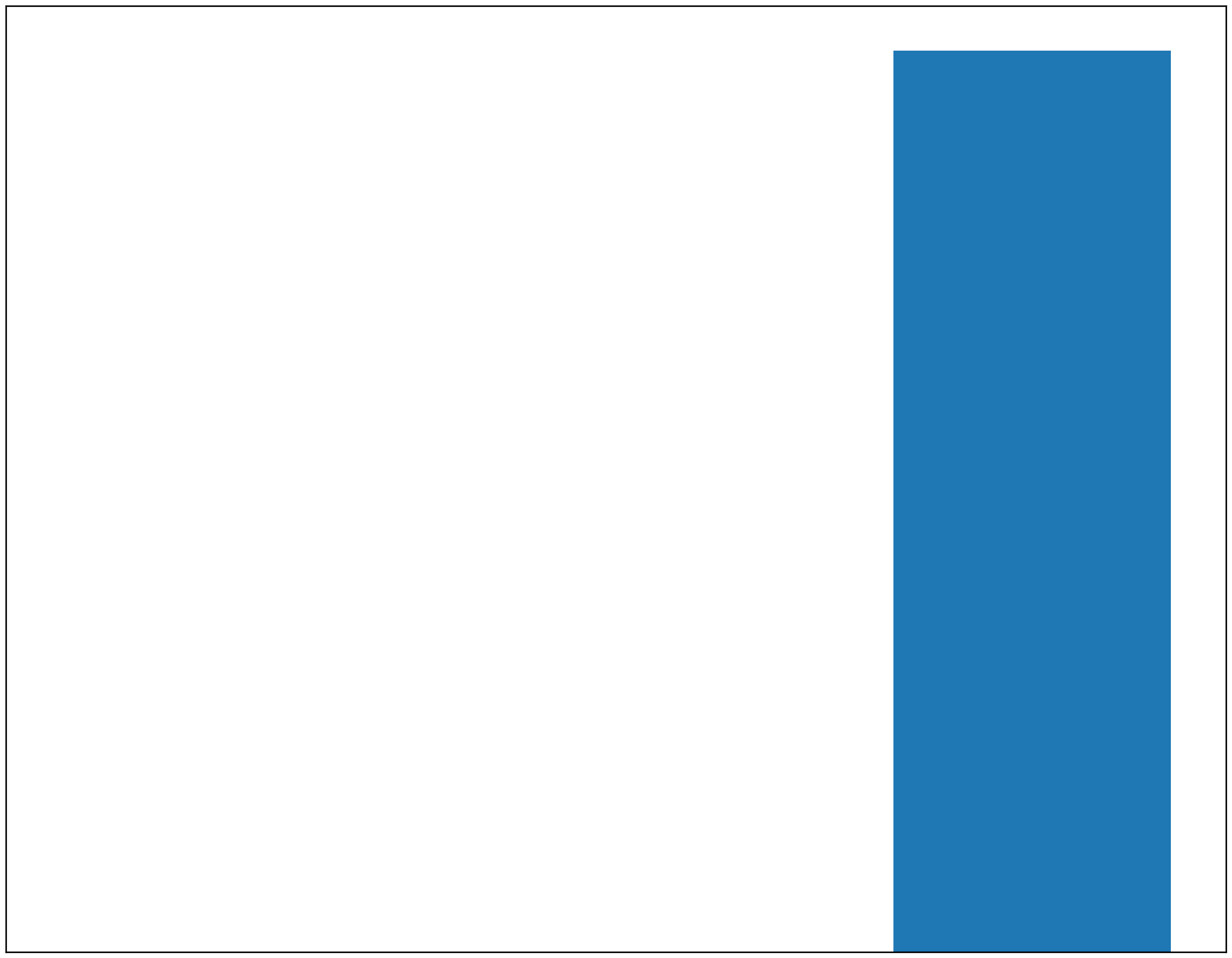
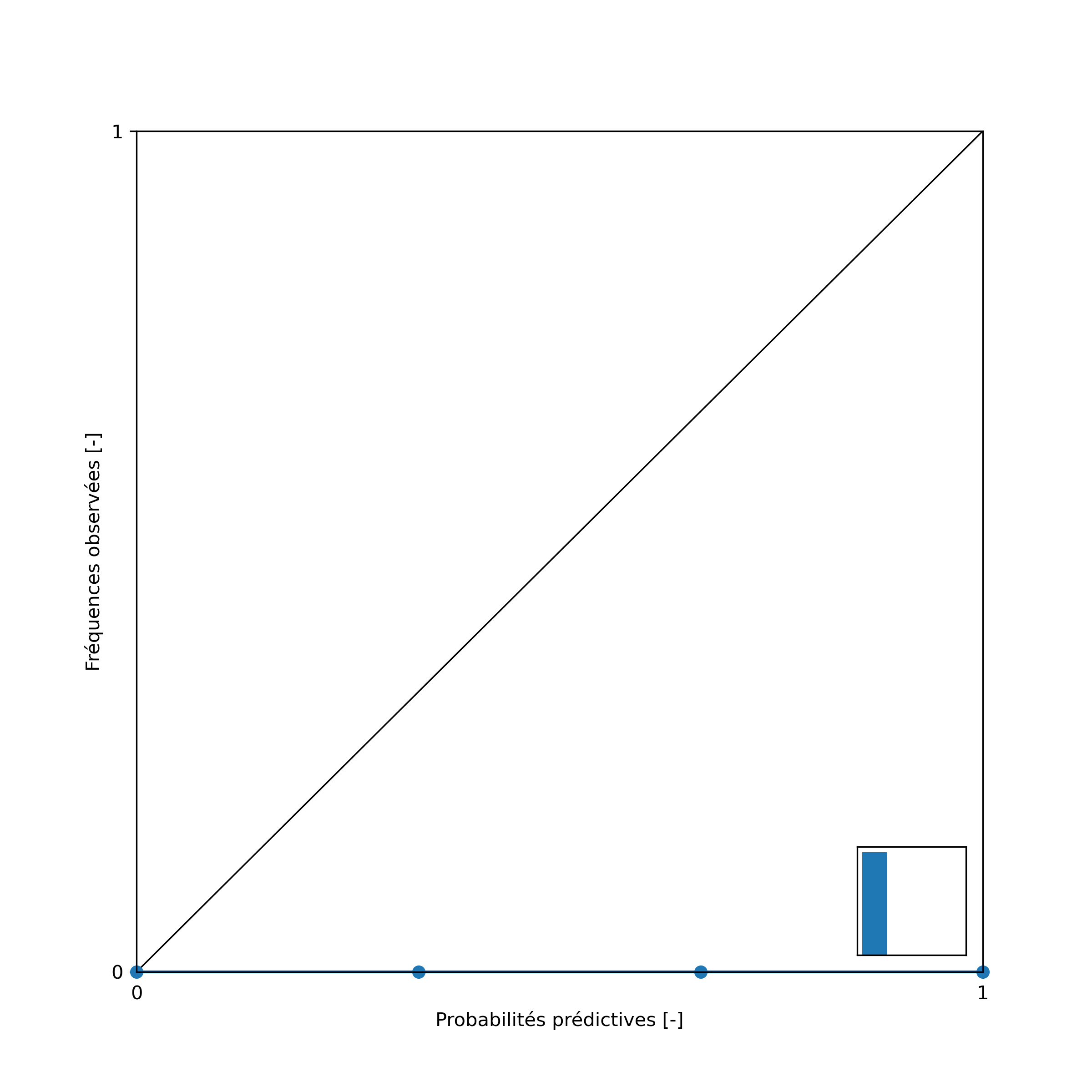
Diagramme de fiabilité
from evalhyd.vigicrues.plot import plot_rel_diag
filepaths_rel_diag = plot_rel_diag(dict_df_prb['REL_DIAG'], output_dir='tutoriel/figs')
from IPython.display import Image
Image(filepaths_rel_diag[0])